c13o <- read_csv(here::here("data-output/legacy/groups_ALL.csv"))
dt0 <- read_rds(here::here("data-interim/objemy_pocty_scraped_raw_2012_2018.rds"))Počty úředníků: 2003-2018
unique(c13o$variable) %>% enframe(name = NULL)# A tibble: 25 x 1
value
<chr>
1 AvgSal_schvaleny
2 AvgSal_upraveny
3 Zam_schvaleny
4 PlatyOPPP_schvaleny
5 OPPP_upr2skut
6 Zam_uprMinusskut
7 PlatyOPPP_skutecnost
8 OPPP_upraveny
9 PlatyOPPP_upr2skut
10 OPPP_uprMinusskut
# … with 15 more rowsunique(c13o$grp) %>% enframe(name = NULL)# A tibble: 11 x 1
value
<chr>
1 Exekutiva
2 PO
3 OSS-RO
4 UO - Ostatní
5 UO - Ministerstva
6 St. sprava se SOBCPO
7 SOBCPO
8 ROPO celkem
9 OOSS
10 UO
11 OSS-SS unique(dt0$type) %>% enframe(name = NULL)# A tibble: 9 x 1
value
<chr>
1 ÚO
2 jedn. OSS státní správy
3 SOBCPO
4 ST.SPRÁVA
5 ostatní OSS
6 OSS sum
7 PO sum
8 Příslušníci a vojáci
9 jedn. OSSstátní správy Explore & prep to merge
Prep data 2013+
dt <- dt0 %>%
filter(kap_num == "C E L K E M" & indicator == "count") %>%
select(year, grp = type, schvaleny = rozp,
skutecnost, upraveny, rozdil, index, plneni) %>%
mutate(grp = recode(grp,
`jedn. OSS státní správy` = "neústřední st. správa",
`ST.SPRÁVA` = "St. sprava se SOBCPO"),
plneni = 2-plneni/100, rozdil = -rozdil)Prep data 2003+
dto <- c13o %>%
filter(promenna == "Zam") %>%
select(grp, sgrp, variable, value, udaj, promenna, UO, exekutiva, Year) %>%
set_names(tolower(names(.))) %>%
mutate_at(vars(udaj, variable, promenna), tolower) %>%
mutate(year = year(year),
udaj = recode(udaj, upr2skut = "plneni",
uprminusskut = "rozdil"),
grp = recode(grp, UO = "ÚO", `OSS-RO` = "OSS sum",
PO = "PO sum",
`OSS-SS` = "neústřední st. správa",
OOSS = "ostatní OSS")) %>%
filter(grp %in% c("ÚO", "ST.SPRÁVA", "SOBCPO", "OSS sum", "ostatní OSS",
"PO sum", "St. sprava se SOBCPO",
"neústřední st. správa"))Check groupings
2003+
unique(dto$grp) %>% enframe(name = NULL)# A tibble: 7 x 1
value
<chr>
1 OSS sum
2 St. sprava se SOBCPO
3 SOBCPO
4 ostatní OSS
5 PO sum
6 ÚO
7 neústřední st. správa2013+
unique(dt$grp) %>% enframe(name = NULL)# A tibble: 8 x 1
value
<chr>
1 ÚO
2 neústřední st. správa
3 SOBCPO
4 St. sprava se SOBCPO
5 ostatní OSS
6 OSS sum
7 PO sum
8 Příslušníci a vojáci Check data by comparing grouping sizes
2003+
dto %>%
filter(udaj == "schvaleny" & year == 2013) %>%
ggplot(aes(grp, value/1000)) +
geom_col() + coord_flip() + ggtitle("2013 - data 2003-2012") +
scale_y_continuous(limits = c(0,250))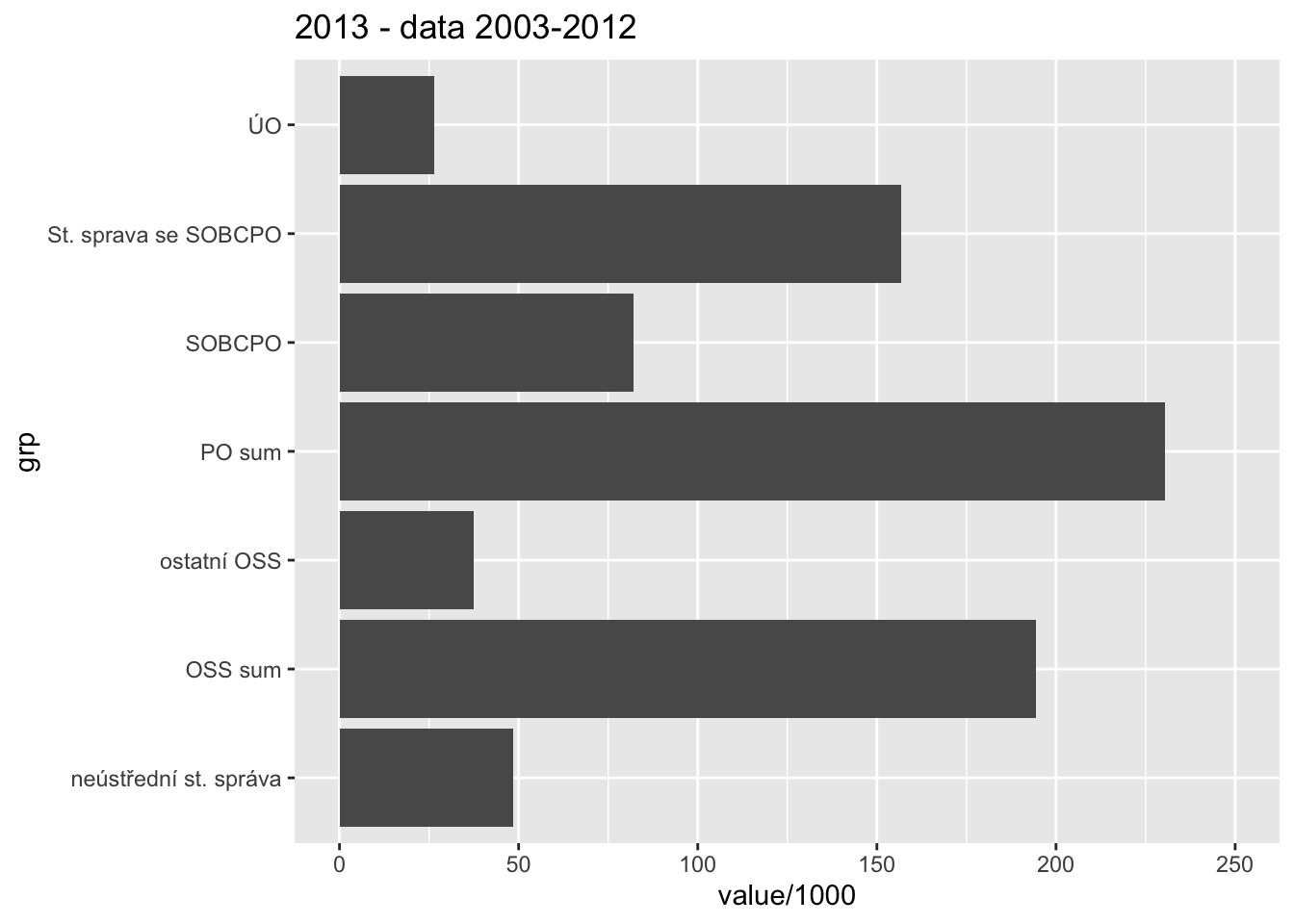
2013+
dt %>%
filter(year == 2013) %>%
filter(!(grp %in% c("Příslušníci a vojáci"))) %>%
ggplot(aes(grp, skutecnost/1e3)) +
geom_col() + coord_flip() + ggtitle("2013 - data 2013-2018") +
scale_y_continuous(limits = c(0,250))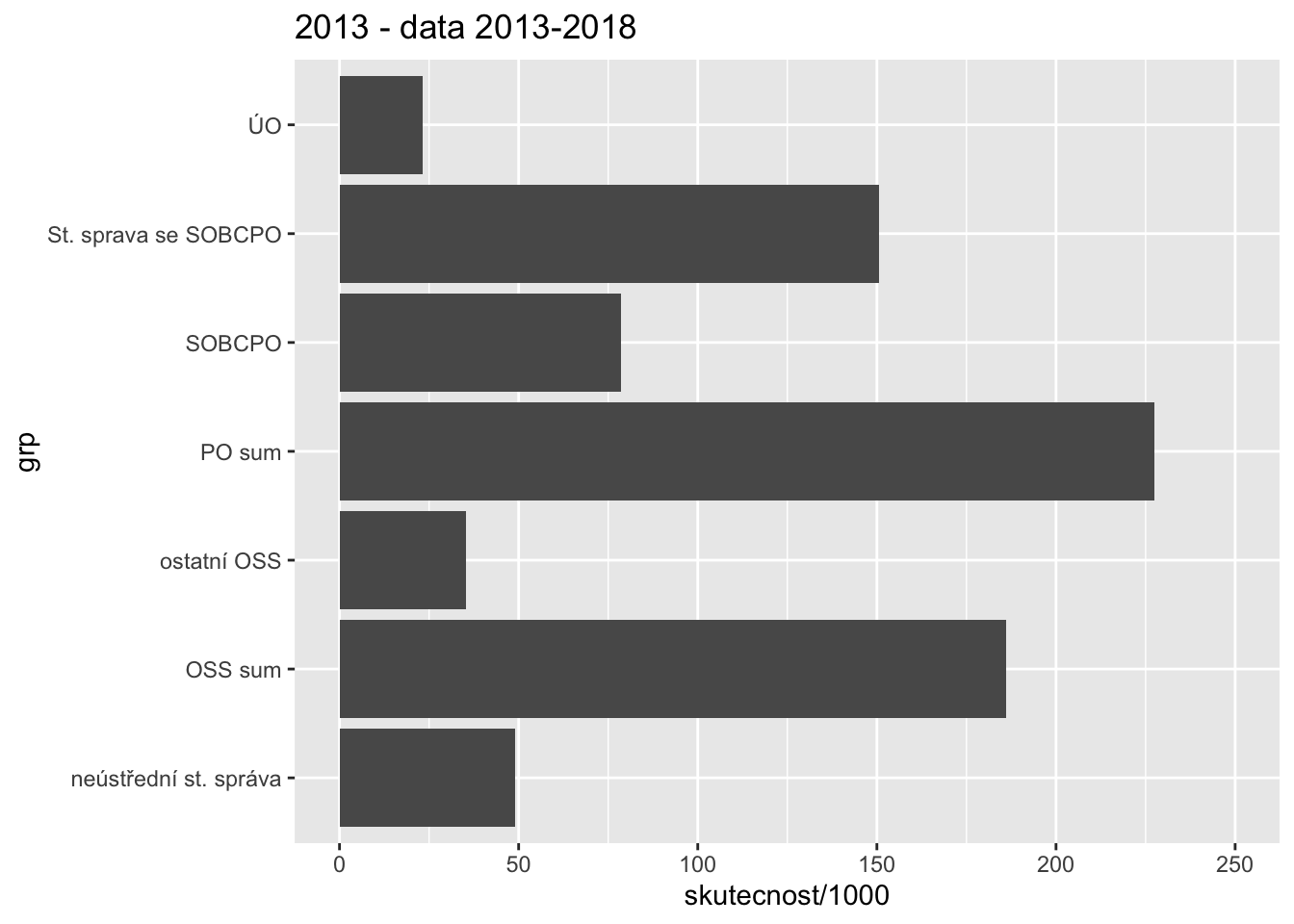
Merge data:
srs <- bind_rows(dto %>% mutate(ds = "old") %>%
filter(year != 2013) %>%
select(year, grp, value, udaj),
dt %>% pivot_longer(names_to = "udaj", values_to = "value",
cols = c(schvaleny, skutecnost,
upraveny, rozdil,
index, plneni)) %>%
mutate(ds = "new", year = as.numeric(year)))First charts
NB:
- skok v roce 2012 je daný redefinicí MV, které od 2012 zahrnuje i velení policie a hasičů
- řada příslušníků a vojáků začíná až v 2013, protože z minulé analýzy jsme je tuším úplně vypustil nebo v interních datech MF nebyli
Absolute - comparable
srs %>%
filter(udaj == "skutecnost") %>%
ggplot(aes(year, value)) +
geom_line() +
facet_wrap(~grp)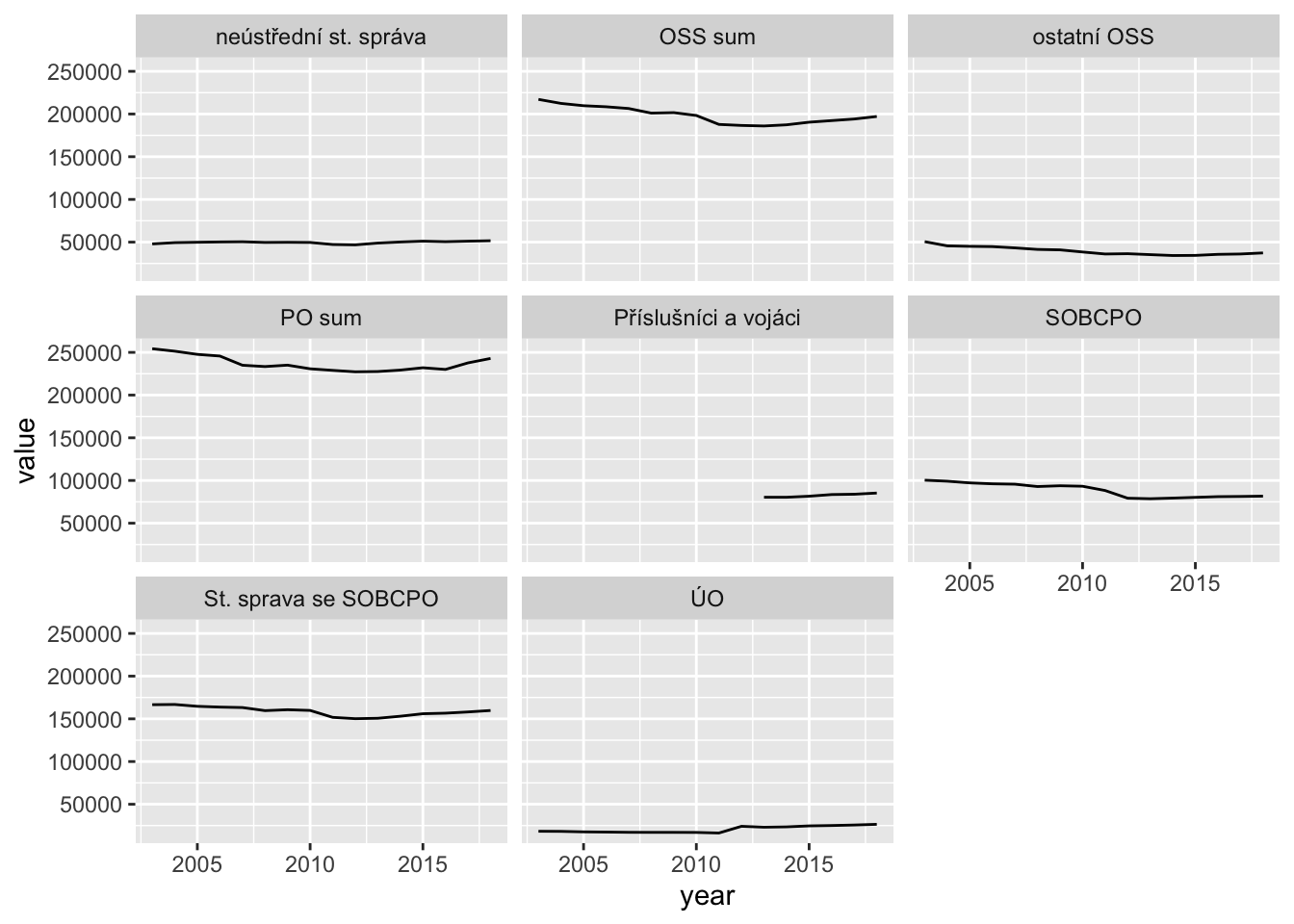
Absolute - focus on changes
srs %>%
filter(udaj == "skutecnost") %>%
ggplot(aes(year, value)) +
geom_line() +
facet_wrap(~grp, scales = "free_y")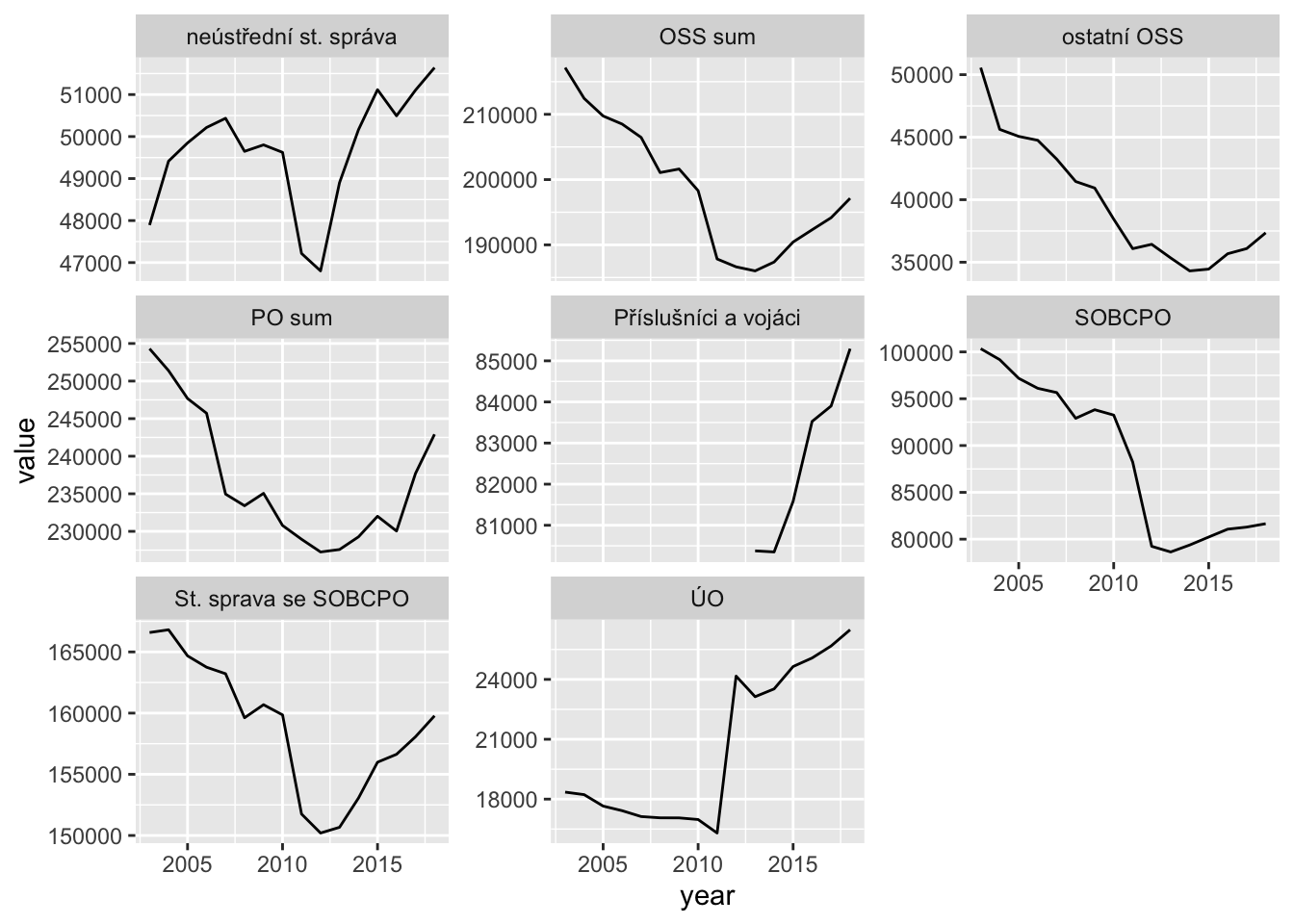
Comparisons
Plan vs. reality
srs %>%
filter(udaj == "plneni") %>%
ggplot(aes(year, 2-value)) +
geom_line() +
facet_wrap(~grp)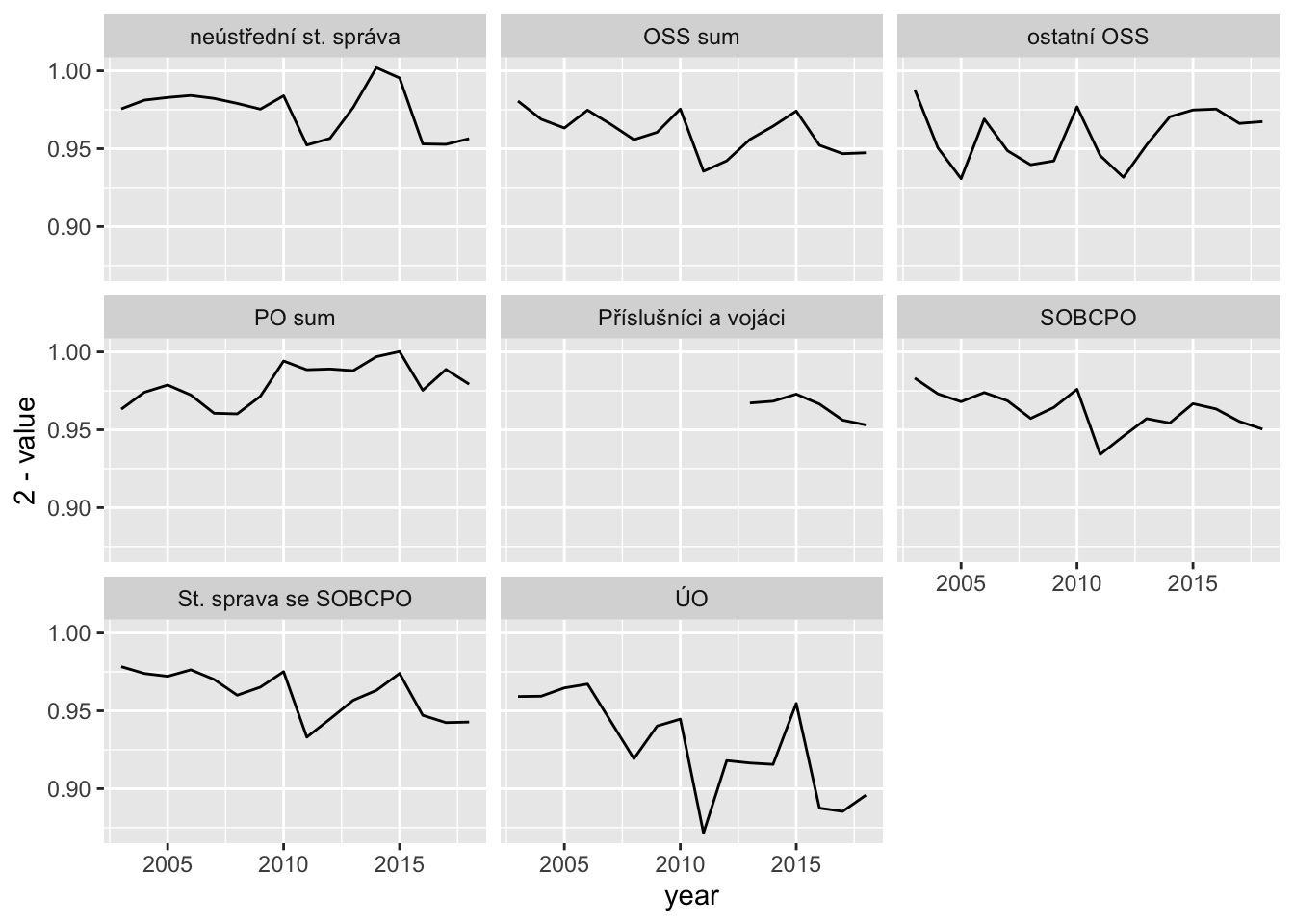
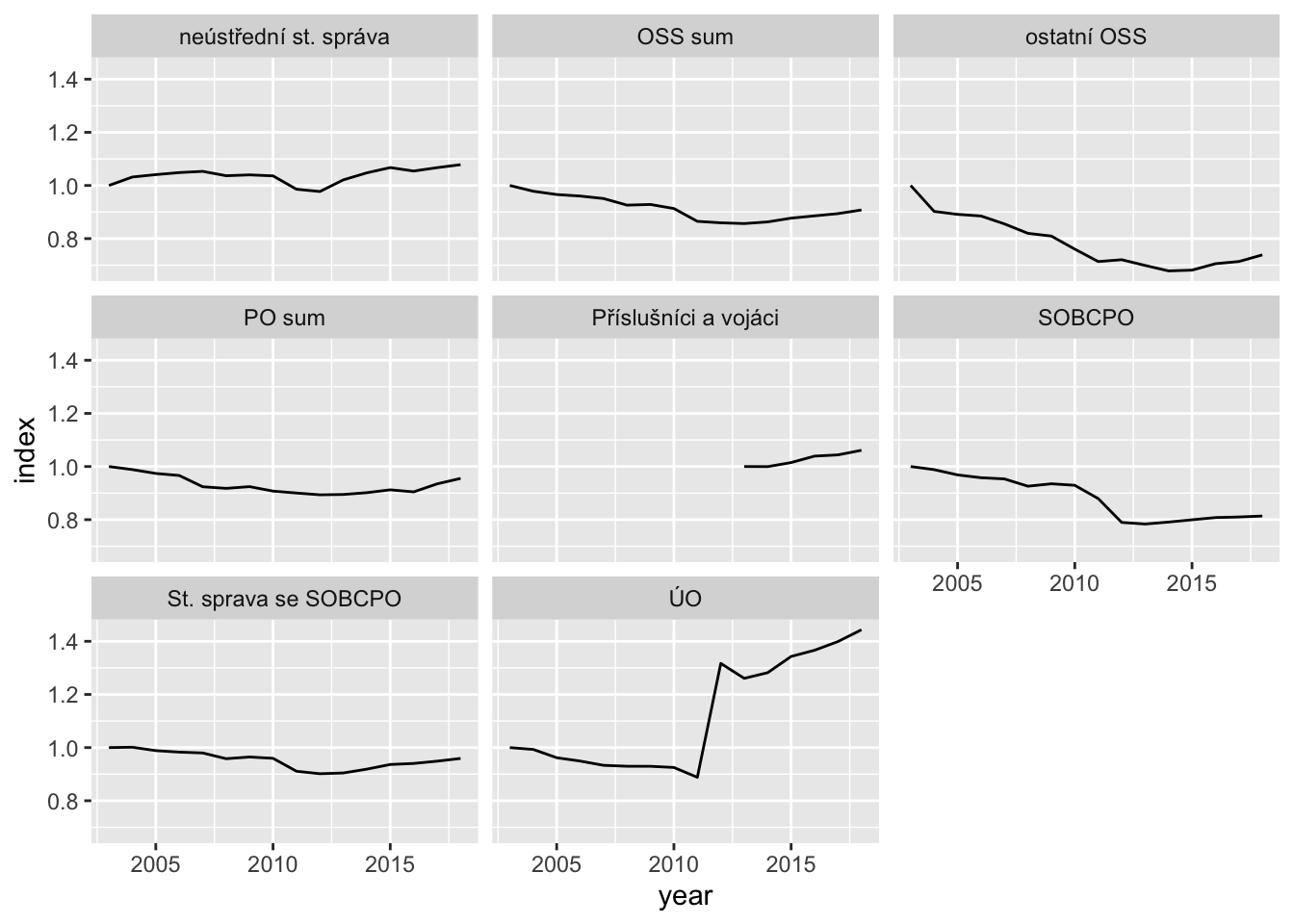
Growth from 2003 base
srs %>%
filter(udaj == "skutecnost") %>%
group_by(grp) %>%
arrange(year) %>%
mutate(index = value/first(value)) %>%
ggplot(aes(year, index)) +
geom_line() +
facet_wrap(~grp)